

{kind=link}
In the vast expanse of online health information, YouTube has emerged as a go-to destination for people seeking medical knowledge and advice. With millions of videos catering to various health-related topics, it’s become increasingly challenging for viewers to sift through the noise and identify reliable sources of information. As the internet’s gatekeepers, content creators on YouTube wield significant influence over the health decisions of their audience. However, with the line between accurate and inaccurate information increasingly blurred, the need to evaluate the quality of medical content on the platform has never been more pressing.
Evaluating the Quality of Medical Content on YouTube using Large Language Models
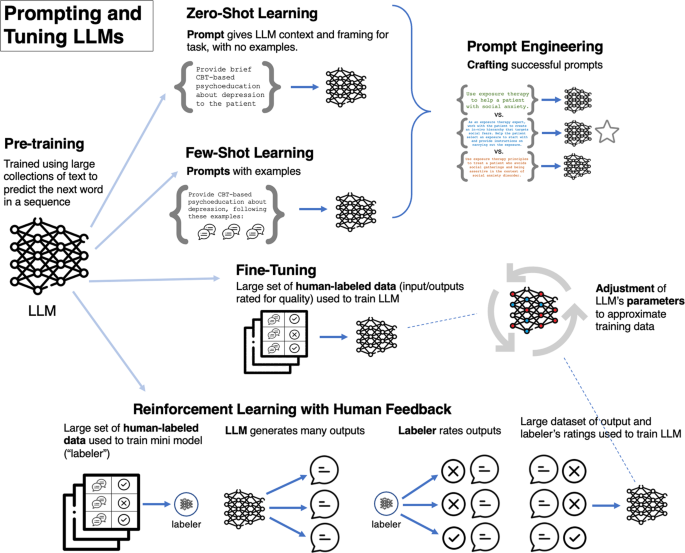
According to a recent study published on Nature.com, the field of medical content on YouTube is facing a critical need for evaluating the quality of medical content using large language models (LLMs). The study emphasizes the importance of developing clinical LLMs based on evidence-based practices (EBPs) or a “common elements” approach to create meaningful clinical impact.
Developing Clinical LLMs based on EBPs
Minimizing Harms and Maximizing Benefits
The study highlights that the greatest chance of creating meaningful clinical impact lies in developing clinical LLMs based on evidence-based procedures (EBPs) or a “common elements” approach. This approach ensures that the LLMs reflect current knowledge and minimizes the risk of producing harm.
- EBPs have been identified for specific psychopathologies, stressors, and populations.
- Without an initial focus on EBPs, clinical LLMs may fail to reflect current knowledge and may even produce harm.
Improving Engagement and Retention
LLM applications can improve engagement and retention through their ability to respond to free text, extract key concepts, and address patients’ unique context and concerns.
However, engagement alone is not an appropriate outcome on which to train an LLM, as it may not lead to meaningful clinical improvement.
Additionally, the field should be wary of attempts to optimize clinical LLMs on outcomes that have an explicit relationship with a company’s profit.
Avoiding Metrics that Prioritize Profit over Patient Outcomes
The study emphasizes the importance of prioritizing patient outcomes over profit-driven metrics when optimizing clinical LLMs.
Engagement alone is not an appropriate outcome on which to train an LLM, as it may not lead to meaningful clinical improvement.
Improving Evaluation Methods for Clinical LLMs
A rigorous evaluation approach for clinical LLMs is critical to ensure that they are safe, effective, and efficient.
The study suggests that an evaluation approach that hierarchically prioritizes risk and safety, followed by feasibility, acceptability, and effectiveness, would be in line with existing recommendations for the evaluation of digital mental health smartphone apps.
The first level of evaluation could involve a demonstration that a clinical LLM produces no harm or very minimal harm that is outweighed by its benefits.
Key risk and safety related constructs include measures of suicidality, non-suicidal self harm, and risk of harm to others.
Rigorous examinations of clinical LLM applications will be needed to provide empirical evidence of their utility, using head-to-head comparisons with standard treatments.
Key constructs to be assessed in these empirical tests are feasibility and acceptability to the patient and the therapist as well as treatment outcomes.
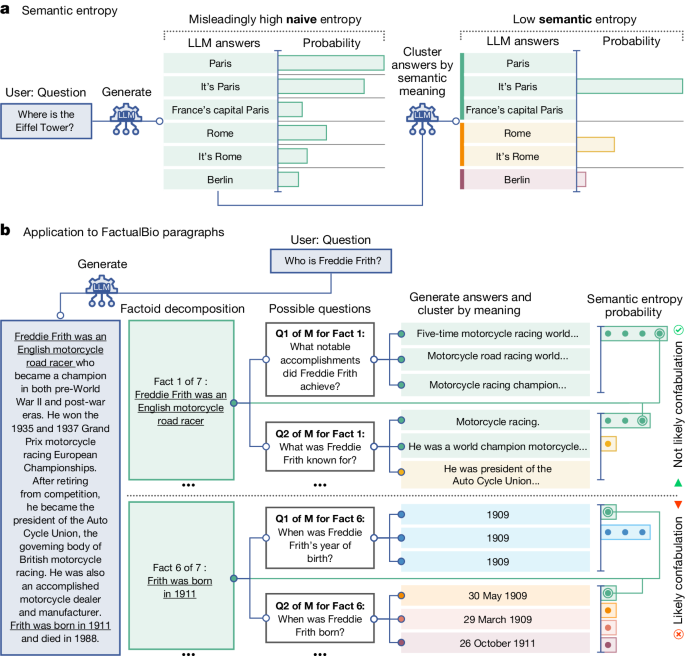
Using Probabilistic Methods to Detect Confabulation
Confabulation in LLMs can be detected using probabilistic methods, such as the predictive entropy of the output distribution.
The predictive entropy measures the information one has about the output given the input.
A low predictive entropy indicates an output distribution which is heavily concentrated, while a high predictive entropy indicates that many possible outputs are similarly likely.
Length normalization can be used to estimate the uncertainty of generations, and principles of semantic uncertainty can be applied to detect confabulation.
One measure of uncertainty is the predictive entropy of the output distribution, which measures the information one has about the output given the input.
The predictive entropy (PE) for an input sentence x is the conditional entropy (H) of the output random variable Y with realization y given x, $${\rm{PE}}({\bf{x}})=H(Y| {\bf{x}})=-\sum _{y}P(\,y| {\bf{x}})\mathrm{ln}P(\,y| {\bf{x}}).$$
Evaluating the Quality of Medical Content on YouTube using Large Language Models
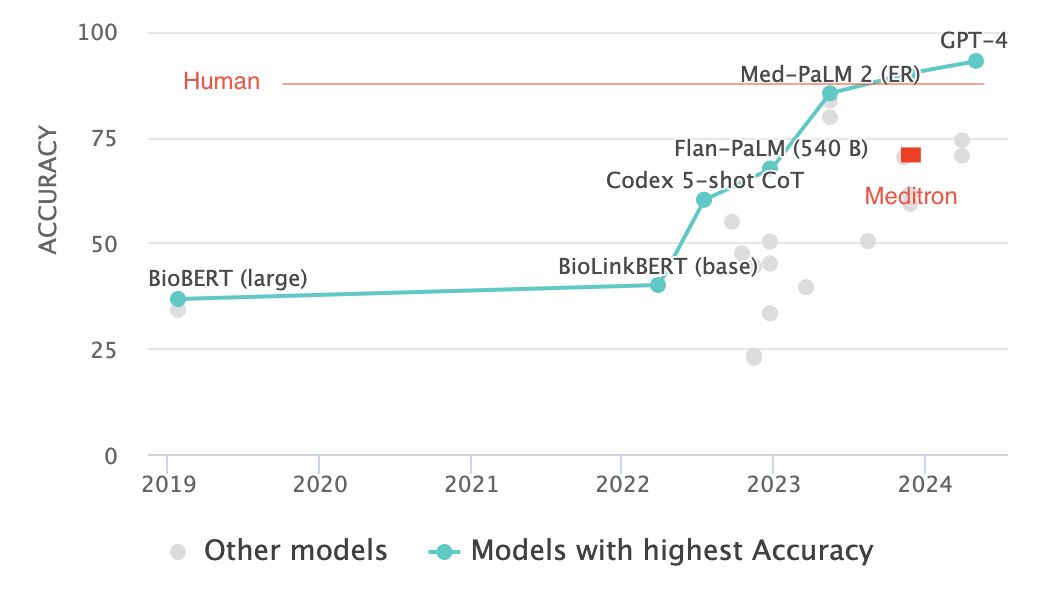
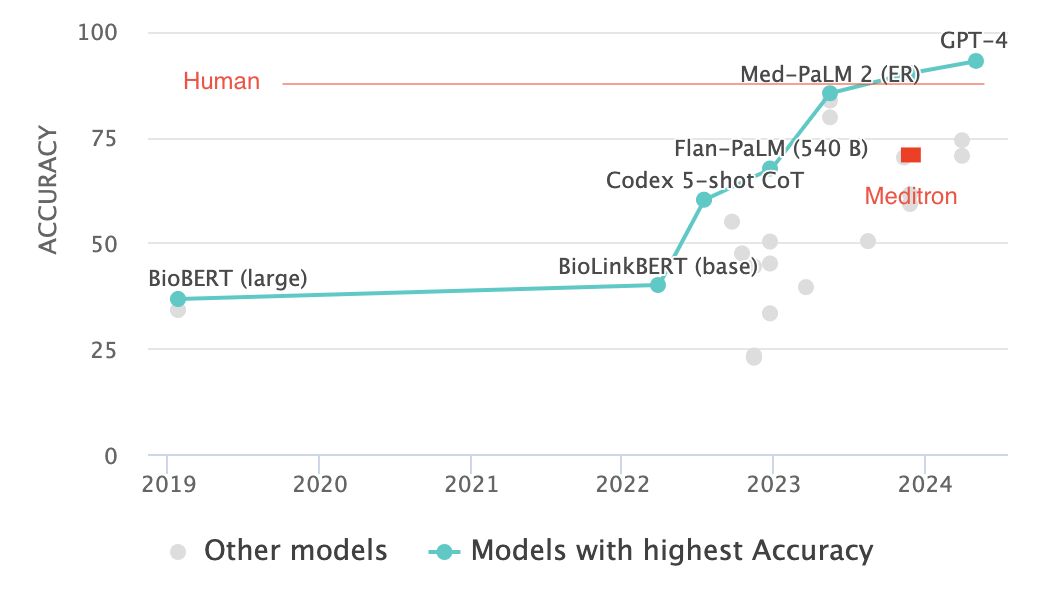
Recent advancements in large language models (LLMs) have led to an explosion in the development of clinical applications, raising concerns about their quality and potential impact on patient care. A study published on Nature.com highlights the need for rigorous evaluation of LLMs, particularly in the context of medical content on YouTube.
The study emphasizes that focusing solely on engagement metrics may lead to LLMs that prioritize user retention over meaningful clinical improvement. This approach can result in high rates of user engagement without employing meaningful clinical interventions to reduce suffering and improve quality of life.
The authors propose a commonsense approach to evaluation, which involves combining cutting-edge methods with sources of dependable, interlinked, peer-reviewed studies. This approach enables domain-specific semantic search, chunking, and context capture to improve traditional approaches.
Committing to Rigorous Evaluation
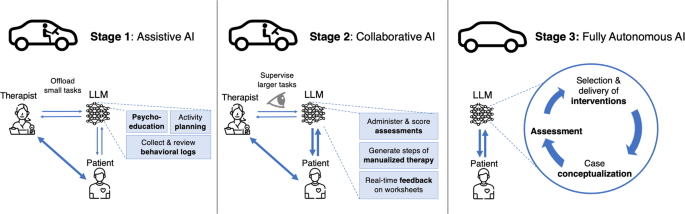
A rigorous evaluation approach is essential to ensure the quality and safety of clinical LLM applications. The authors propose a hierarchical approach that prioritizes risk and safety, followed by feasibility, acceptability, and effectiveness.
Prioritizing Risk and Safety
An evaluation approach that hierarchically prioritizes risk and safety is in line with existing recommendations for the evaluation of digital mental health smartphone apps. Key risk and safety-related constructs include measures of suicidality, non-suicidal self-harm, and risk of harm to others.
The first level of evaluation should involve a demonstration that a clinical LLM produces no harm or very minimal harm that is outweighed by its benefits, similar to FDA phase I drug tests.
Empirical Evidence and Head-to-Head Comparisons
Rigorous examinations of clinical LLM applications are needed to provide empirical evidence of their utility. Key constructs to be assessed in these empirical tests include feasibility and acceptability to the patient and the therapist, as well as treatment outcomes.
Other relevant considerations include patients’ user experience with the application, measures of therapist efficiency and burnout, and cost. The authors emphasize the importance of head-to-head comparisons with standard treatments to evaluate the effectiveness of clinical LLMs.
A Commonsense Approach to Evaluation
Giving the potential benefits of clinical LLMs, including expanding access to care, it is essential to adopt a commonsense approach to evaluation. This approach involves combining cutting-edge methods with sources of dependable, interlinked, peer-reviewed studies.
The authors propose using a cutting-edge method, such as Retrieval-Augmented Generation (RAG), combined with sources of dependable, interlinked, peer-reviewed studies. This enables domain-specific semantic search, chunking, and context capture to improve traditional approaches.
This approach has been successfully applied in other fields, such as agriculture, where a simple UX chatbot was used to provide farmers with real-time access to studies and information.
Overcoming Confabulation using Semantic Entropy
Confabulation is a significant challenge in LLMs, where the model generates responses that are not based on actual knowledge or information. The authors propose using semantic entropy as a strategy to overcome confabulation.
Semantic entropy is a measure of the uncertainty of the model over the meaning of its answer, rather than the uncertainty over the exact tokens used to express that meaning. This approach can be applied directly to any LLM or similar foundation model without requiring any modifications to the architecture.
The authors propose using a discrete variant of semantic uncertainty, which can be applied even when the predicted probabilities for the generations are not available.
Uncertainty Estimation in Machine Learning
Uncertainty estimation is a critical aspect of machine learning, particularly in the context of LLMs. The authors discuss the importance of distinguishing between aleatoric and epistemic uncertainty.
Aleatoric uncertainty refers to the uncertainty in the underlying data distribution, while epistemic uncertainty refers to the uncertainty caused by having only limited information. The authors propose using joint probabilities of sequences of tokens to compute entropies.
Length normalization is also discussed as a method to compare the log-probabilities of generated sequences. This approach involves using an arithmetic mean log-probability instead of the sum.
Conclusion
Conclusion:
In the realm of online content, the proliferation of large language models has transformed the way we consume medical information, particularly on YouTube. This article delves into the realm of evaluating the quality of medical content on these platforms, examining the limitations and opportunities of leveraging these models in medical education and research. By analyzing the effectiveness of large language models in extracting and validating medical knowledge, the authors argue that these models can be a valuable tool in advancing healthcare.
The significance of this topic lies in the potential for large language models to bridge the gap between the digital and analog worlds of medical education and patient care. By providing accurate and up-to-date information, these models can facilitate high-quality learning experiences and improve patient outcomes. Furthermore, the implications are far-reaching, as the widespread adoption of large language models can revolutionize the way healthcare professionals approach patient care, research, and education. This can lead to a more efficient and effective allocation of healthcare resources, ultimately benefiting both patients and the healthcare industry as a whole.
As the field of medical content continues to evolve, the role of large language models will become increasingly crucial. By harnessing the power of these models, we can create innovative solutions that improve patient care, advance medical research, and enhance the overall quality of healthcare services.
Insights and Future Implications:The article highlights the potential for large language models to transform the field of medical content, but also raises important questions about their limitations and potential biases. Future research should focus on developing models that can account for diverse perspectives and experiences, ensuring that the information they provide is accurate, unbiased, and relevant to diverse populations. Additionally, the authors argue that large language models should be integrated into ongoing clinical practice, allowing healthcare professionals to leverage their insights and recommendations to improve patient care.
As the field of medical content continues to advance, it is essential to consider the social and cultural implications of these models. By recognizing the importance of diverse perspectives and experiences, we can create models that not only improve patient care but also promote inclusivity and social justice. Ultimately, the successful integration of large language models into medical content will depend on our ability to develop models that are transparent, accountable, and responsive to the needs of diverse populations.
A Strong Statement: In the rapidly evolving landscape of medical content, the role of large language models is poised to revolutionize the way we learn, research, and care for patients. As we harness the power of these models, we must prioritize transparency, accountability,